(there is much more information about neural networks elsewhere online if you are interested in reading further)
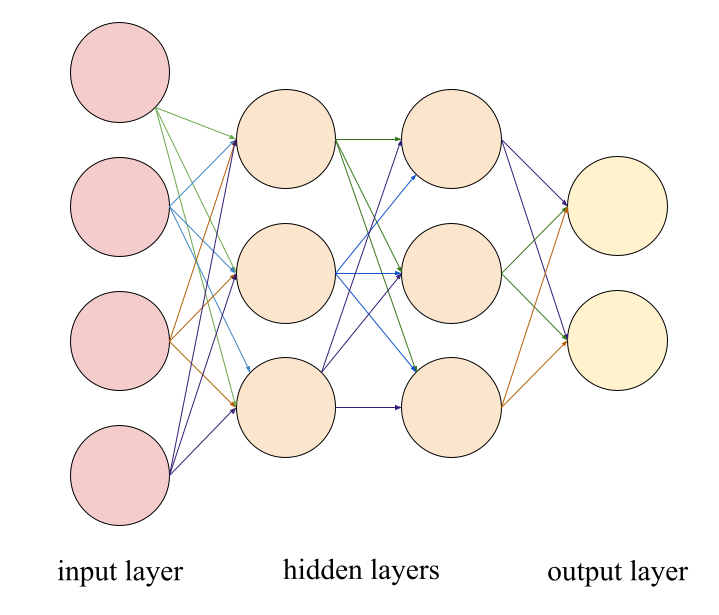
Neural networks are called as such since they are comparable to the human brain. Similar to the brain, each neural network is composed of neurons, though they are arranged in layers, with each layer altering the next in a way that eventually results in an outcome that can be interpreted from the data stored in the last layer of neurons. Each connection between two neurons in a neural network has a weight that determines the importance of the data in the previous neuron in determining the data in the next neuron. To get the data that is passed on to a given neuron, the neurons at the beginning of each connection leading into it are multiplied by their respective weights.
simple diagram of a neural network
Each neuron also has a bias, which manipulates the weighted value and changes how it will be affected by the activation function (see below).
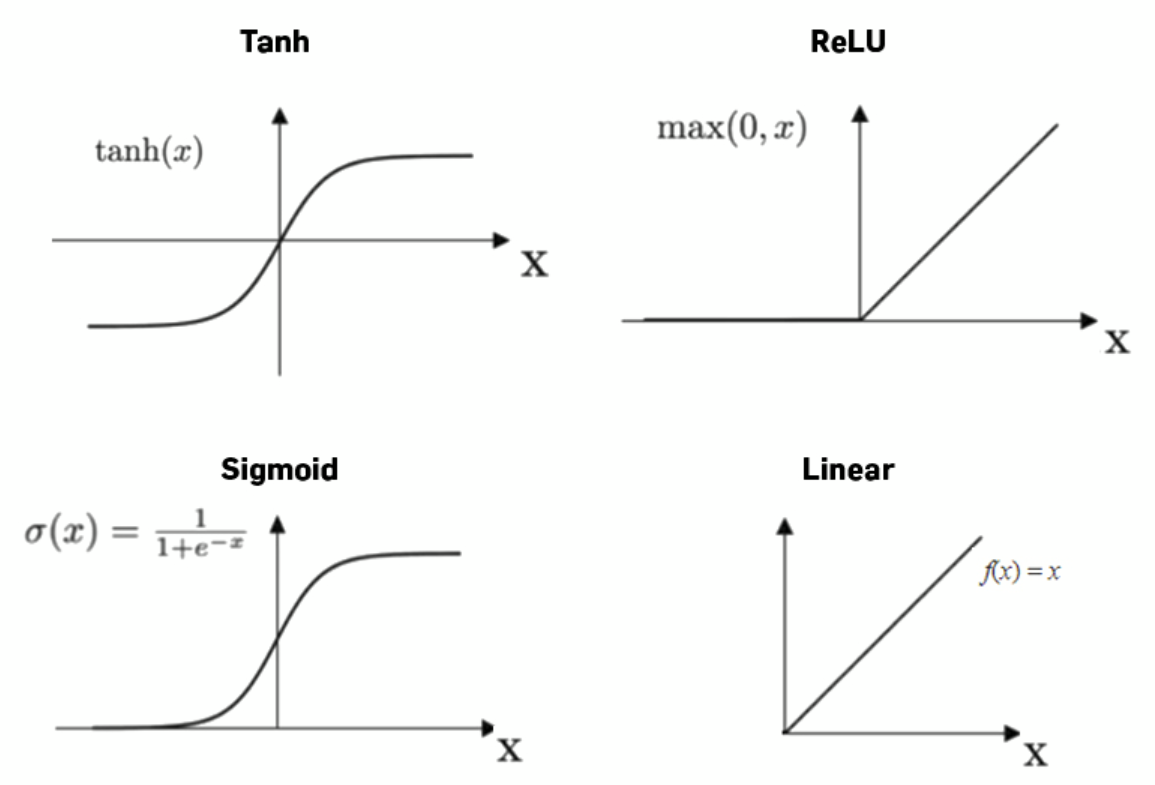
Each neuron's newly determined value passes through an activation function before being used for the next neuron. Nonlinear activation functions allow for more complex manipulation of data. Common activation functions include sigmoid (1⁄(1+e-x)) and tanh, though ReLU (max(0,x)) is most commonly used since it prevents the issues of vanishing and exploding gradients during backpropagation (see below).
"Training" a neural network means determining the weights of each connection and the biases of each neuron. Neural networks essentially train themselves if given a sufficient amount of training data. The network’s output when each piece of data is inputted is compared to the information it was supposed to output. The weights and biases are changed in order to make it more likely that inputting a piece of information will result in the desired outcome.
To do this, the network determines the cost (inaccuracy) of the outcome of one or more inputs given a certain set of weights and biases. The program then determines what minor change to the weights and/or biases will result in the greatest cost decrease through backpropagation. The process is repeated until there are no more minor changes that can be made to further decrease cost. The weights and biases may end up at a local minimum (meaning that there is another possible combination that would result in an even lower cost, even though it would require a seemingly arbitrary major change), and while there are ways to mitigate the chance of this occurring, the issue is ultimately unable to be completely resolved.
How Backpropagation Works
Backpropagation finds the overall change to the weights and biases of the neural network by finding the necessary change for each neuron in order to best match the desired output. The process occurs separately for each piece of training data. For a given piece of training data, the process starts at the output neurons, and the desired changes of each of the output neurons (which, if implemented, would result in the desired output given the input).
There are a few ways to change each connection:
change the bias - makes the neuron more or less sensitive
change the weights
If output is too low, increase weights of the neurons in the previous layer with high values
If output is too high, decrease weights of the neurons in the previous layer with high values
change the values of the neurons in the previous layer
If output is too low, increase values of positively-weighted neurons and decrease values of negatively-weighted neurons (and vice versa)
The desired changes of the output neurons are added together in order to get the changes that should be made to the neurons in the previous layer.
The same process occurs for the neurons in the previous layer and each subsequent layer, but with the desired changes gotten from the previous step (next layer) as the desired changes of the neurons.
These steps are repeated for each piece of training data. The changes from each iteration are averaged, and those changes should be made for the cost function to descend the most (the changes essentially represent the direction the cost function needs to move).
Still, many movements need to be made to determine the minimum, so the entire process up to this point is repeated until there are no more changes that could be made to decrease the cost and make the network more accurate.
Since backpropagation requires a lot of processing, another way of minimizing the value of the cost function, called stochastic gradient descent, can be used.
In stochastic gradient descent, the training data set is randomly portioned into many different, smaller sets. Each point movement towards the minimum only uses a part of the entire data set. While this results in less accurate movements, it yields similar results in the end.